![]()
[Feb-2024] AWS Certified Solutions Architect SAA-C03 Exam Practice Test Questions Dumps Bundle!
2024 Updated SAA-C03 PDF for the SAA-C03 Tests Free Updated Today!
The Amazon SAA-C03 exam tests the candidate's knowledge of AWS services such as EC2, S3, RDS, VPC, and IAM, among others. It also assesses their ability to design and deploy highly available, cost-effective, and scalable systems on AWS. SAA-C03 exam consists of 65 multiple-choice and multiple-response questions, and the duration is 130 minutes.
NEW QUESTION # 224
A company plans to migrate a MySQL database from an on-premises data center to the AWS Cloud.
This database will be used by a legacy batch application that has steady-state workloads in the morning but has its peak load at night for the end-of-day processing. You need to choose an EBS volume that can handle a maximum of 450 GB of data and can also be used as the system boot volume for your EC2 instance.
Which of the following is the most cost-effective storage type to use in this scenario?
- A. Amazon EBS Throughput Optimized HDD (st1)
- B. Amazon EBS Cold HDD (sc1)
- C. Amazon EBS General Purpose SSD (gp2)
- D. Amazon EBS Provisioned IOPS SSD (io1)
Answer: C
Explanation:
In this scenario, a legacy batch application which has steady-state workloads requires a relational MySQL database. The EBS volume that you should use has to handle a maximum of 450 GB of data and can also be used as the system boot volume for your EC2 instance. Since HDD volumes cannot be used as a bootable volume, we can narrow down our options by selecting SSD volumes. In addition, SSD volumes are more suitable for transactional database workloads, as shown in the table below: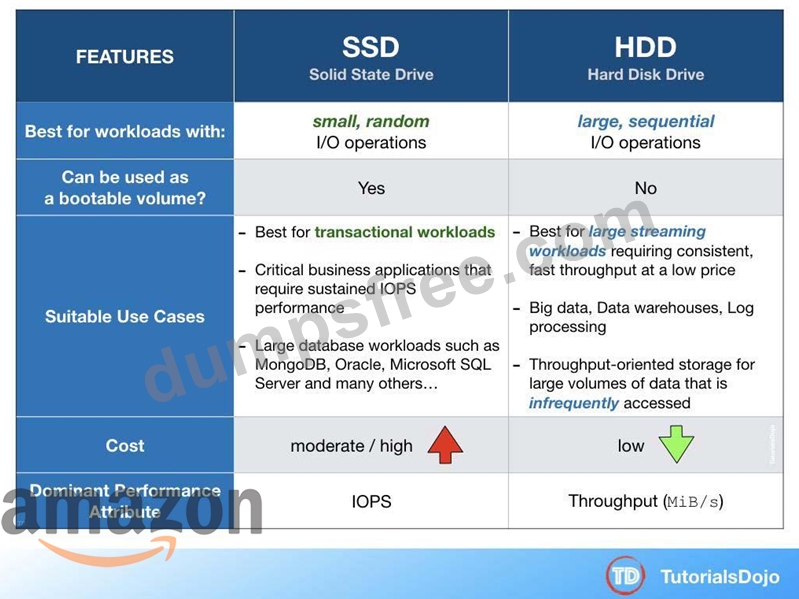
General Purpose SSD (gp2) volumes offer cost-effective storage that is ideal for a broad range of workloads. These volumes deliver single-digit millisecond latencies and the ability to burst to 3,000 IOPS for extended periods of time. AWS designs gp2 volumes to deliver the provisioned performance 99% of the time. A gp2 volume can range in size from 1 GiB to 16 TiB.
Amazon EBS Provisioned IOPS SSD (io1) is incorrect because this is not the most cost-effective EBS type and is primarily used for critical business applications that require sustained IOPS performance.
Amazon EBS Throughput Optimized HDD (st1) is incorrect because this is primarily used for frequently accessed, throughput-intensive workloads. Although it is a low-cost HDD volume, it cannot be used as a system boot volume.
Amazon EBS Cold HDD (sc1) is incorrect. Although Amazon EBS Cold HDD provides lower cost HDD volume compared to General Purpose SSD, it cannot be used as a system boot volume.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSVolumeTypes.html#EBSVolumeTypes_gp
2
Amazon EBS Overview - SSD vs HDD:
https://www.youtube.com/watch?v=LW7x8wyLFvw
Check out this Amazon EBS Cheat Sheet:
https://tutorialsdojo.com/amazon-ebs/
NEW QUESTION # 225
A company has a decoupled application in AWS using EC2, Auto Scaling group, S3, and SQS. The Solutions Architect designed the architecture in such a way that the EC2 instances will consume the message from the SQS queue and will automatically scale up or down based on the number of messages in the queue.
In this scenario, which of the following statements is false about SQS?
- A. FIFO queues provide exactly-once processing.
- B. Standard queues preserve the order of messages.
- C. Amazon SQS can help you build a distributed application with decoupled components.
- D. Standard queues provide at-least-once delivery, which means that each message is delivered at least once.
Answer: B
Explanation:
All of the answers are correct except for the option that says: Standard queues preserve the order of messages. Only FIFO queues can preserve the order of messages and not standard queues.
Explanation:
Reference:
https://aws.amazon.com/sqs/faqs/
Check out this Amazon SQS Cheat Sheet:
https://tutorialsdojo.com/amazon-sqs/
Tutorials Dojo's AWS Certified Solutions Architect Associate Exam Study Guide:
https://tutorialsdojo.com/aws-certified-solutions-architect-associate-saa-c02/
NEW QUESTION # 226
A company wants to migrate 100 GB of historical data from an on-premises location to an Amazon S3 bucket. The company has a 100 megabits per second (Mbps) internet connection on premises. The company needs to encrypt the data in transit to the S3 bucket. The company will store new data directly in Amazon S3.
Which solution will meet these requirements with the LEAST operational overhead?
- A. Use AWS DataSync to migrate the data from the on-premises location to an S3 bucket.
- B. Use the s3 sync command in the AWS CLI to move the data directly to an S3 bucket.
- C. Use AWS Snowball to move the data to an S3 bucket.
- D. Set up an IPsec VPN from the on-premises location to AWS. Use the s3 cp command in the AWS CLI to move the data directly to an S3 bucket.
Answer: A
Explanation:
AWS DataSync is a data transfer service that makes it easy for you to move large amounts of data online between on-premises storage and AWS storage services over the internet or AWS Direct Connect. DataSync automatically encrypts your data in transit using TLS encryption, and verifies data integrity during transfer using checksums. DataSync can transfer data up to 10 times faster than open-source tools, and reduces operational overhead by simplifying and automating tasks such as scheduling, monitoring, and resuming transfers. Reference: https://aws.amazon.com/datasync/
NEW QUESTION # 227
A company needs to store its accounting records in Amazon S3. The records must be immediately accessible for 1 year and then must be archived for an additional 9 years. No one at the company, including administrative users and root users, can be able to delete the records during the entire 10-year period. The records must be stored with maximum resiliency.
Which solution will meet these requirements?
- A. Store the records in S3 Glacier for the entire 10-year period. Use an access control policy to deny deletion of the records for a period of 10 years.
- B. Use an S3 Lifecycle policy to transition the records from S3 Standard to S3 Glacier Deep Archive after 1 year. Use S3 Object Lock in compliance mode for a period of 10 years.
- C. Use an S3 Lifecycle policy to transition the records from S3 Standard to S3 One Zone-Infrequent Access (S3 One Zone-IA) after 1 year. Use S3 Object Lock in governance mode for a period of 10 years.
- D. Store the records by using S3 Intelligent-Tiering. Use an IAM policy to deny deletion of the records. After 10 years, change the IAM policy to allow deletion.
Answer: B
NEW QUESTION # 228
A company runs an application using Amazon ECS. The application creates resized versions of an original image and then makes Amazon S3 API calls to store the resized images in Amazon S3.
How can a solutions architect ensure that the application has permission to access Amazon $3?
- A. Create a security group that allows access from Amazon ECS to Amazon $3, and update the launch configuration used by the ECS cluster.
- B. Create an IAM role with S3 permissions, and then specify that role as the taskRoleArn in the task definition.
- C. Update the S3 role in AWS IAM to allow read/write access from Amazon ECS, and then relaunch the container.
- D. Create an IAM user with S3 permissions, and then relaunch the Amazon EC2 instances for the ECS cluster while logged in as this account.
Answer: B
Explanation:
This answer is correct because it allows the application to access Amazon S3 by using an IAM role that is associated with the ECS task. The task role grants permissions to the containers running in the task, and can be used to make AWS API calls from the application code. The taskRoleArn is a parameter in the task definition that specifies the IAM role to use for the task.
Reference:
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task-iam-roles.html
https://docs.aws.amazon.com/AmazonECS/latest/APIReference/API_TaskDefinition.html
NEW QUESTION # 229
A company is deploying a new public web application to AWS. The application will run behind an Application Load Balancer (ALB). The application needs to be encrypted at the edge with an SSL/TLS certificate that is issued by an external certificate authority (CA). The certificate must be rotated each year before the certificate expires.
What should a solutions architect do to meet these requirements?
- A. Use AWS Certificate Manager (ACM) to issue an SSL/TLS certificate. Apply the certificate to the ALB.
Use the managed renewal feature to automatically rotate the certificate. - B. Use AWS Certificate Manager (ACM) to issue an SSL/TLS certificate. Import the key material from the certificate. Apply the certificate to the ALB. Use the managed renewal feature to automatically rotate the certificate.
- C. Use AWS Certificate Manager (ACM) to import an SSL/TLS certificate. Apply the certificate to the ALB. Use Amazon EventBridge (Amazon CloudWatch Events) to send a notification when the certificate is nearing expiration. Rotate the certificate manually.
- D. Use AWS Certificate Manager (ACM) Private Certificate Authority to issue an SSL/TLS certificate from the root CA. Apply the certificate to the ALB. Use the managed renewal feature to automatically rotate the certificate.
Answer: C
NEW QUESTION # 230
A hospital is designing a new application that gathers symptoms from patients. The hospital has decided to use Amazon Simple Queue Service (Amazon SOS) and Amazon Simple Notification Service (Amazon SNS) in the architecture.
A solutions architect is reviewing the infrastructure design Data must be encrypted at test and in transit. Only authorized personnel of the hospital should be able to access the data.
Which combination of steps should the solutions architect take to meet these requirements? (Select TWO.)
- A. Turn on server-side encryption on the SOS components by using an AWS Key Management Service (AWS KMS) customer managed key. Apply an IAM pokey to restrict key usage to a set of authorized principals. Set a condition in the queue pokey to allow only encrypted connections over TLS
- B. Turn on server-side encryption on the SQS components Update tie default key policy to restrict key usage to a set of authorized principals.
- C. Turn on server-side encryption on the SNS components by using an AWS Key Management Service (AWS KMS) customer managed key Apply a key policy to restrict key usage to a set of authorized principals.
- D. Turn on encryption on the SNS components Update the default key policy to restrict key usage to a set of authorized principals. Set a condition in the topic pokey to allow only encrypted connections over TLS.
- E. Turn on server-side encryption on the SOS components by using an AWS Key Management Service (AWS KMS) customer managed key Apply a key pokey to restrict key usage to a set of authorized principals. Set a condition in the queue pokey to allow only encrypted connections over TLS.
Answer: C,E
NEW QUESTION # 231
An application development team is designing a microservice that will convert large images to smaller, compressed images. When a user uploads an image through the web interface, the microservice should store the image in an Amazon S3 bucket, process and compress the image with an AWS Lambda function, and store the image in its compressed form in a different S3 bucket.
A solutions architect needs to design a solution that uses durable, stateless components to process the images automatically.
Which combination of actions will meet these requirements? (Choose two.)
- A. Configure an Amazon EventBridge (Amazon CloudWatch Events) event to monitor the S3 bucket When an image is uploaded. send an alert to an Amazon Simple Notification Service (Amazon SNS) topic with the application owner's email address for further processing
- B. Create an Amazon Simple Queue Service (Amazon SQS) queue Configure the S3 bucket to send a notification to the SQS queue when an image is uploaded to the S3 bucket
- C. Launch an Amazon EC2 instance to monitor an Amazon Simple Queue Service (Amazon SQS) queue When items are added to the queue log the file name in a text file on the EC2 instance and invoke the Lambda function
- D. Configure the Lambda function to monitor the S3 bucket for new uploads When an uploaded image is detected write the file name to a text file in memory and use the text file to keep track of the images that were processed
- E. Configure the Lambda function to use the Amazon Simple Queue Service (Amazon SQS) queue as the invocation source When the SQS message is successfully processed, delete the message in the queue
Answer: B,E
Explanation:
Creating an Amazon Simple Queue Service (SQS) queue and configuring the S3 bucket to send a notification to the SQS queue when an image is uploaded to the S3 bucket will ensure that the Lambda function is triggered in a stateless and durable manner.
Configuring the Lambda function to use the SQS queue as the invocation source, and deleting the message in the queue after it is successfully processed will ensure that the Lambda function processes the image in a stateless and durable manner.
Amazon SQS is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications. SQS eliminates the complexity and overhead associated with managing and operating-message oriented middleware, and empowers developers to focus on differentiating work. When new images are uploaded to the S3 bucket, SQS will trigger the Lambda function to process the image and compress it. Once the image is processed, the SQS message is deleted, ensuring that the Lambda function is stateless and durable.
NEW QUESTION # 232
A company has a mulli-tier application that runs six front-end web servers in an Amazon EC2 Auto Scaling group in a single Availability Zone behind an Application Load Balancer (ALB). A solutions architect needs lo modify the infrastructure to be highly available without modifying the application.
Which architecture should the solutions architect choose that provides high availability?
- A. Create an Auto Scaling template that can be used to quickly create more instances in another Region.
- B. Modify the Auto Scaling group to use three instances across each of two Availability Zones.
- C. Create an Auto Scaling group that uses three Instances across each of tv/o Regions.
- D. Change the ALB in front of the Amazon EC2 instances in a round-robin configuration to balance traffic to the web tier.
Answer: B
Explanation:
High availability can be enabled for this architecture quite simply by modifying the existing Auto Scaling group to use multiple availability zones. The ASG will automatically balance the load so you don't actually need to specify the instances per AZ.
NEW QUESTION # 233
A company has an on-premises server that uses an Oracle database to process and store customer information The company wants to use an AWS database service to achieve higher availability and to improve application performance. The company also wants to offload reporting from its primary database system.
Which solution will meet these requirements in the MOST operationally efficient way?
- A. Use Amazon RDS deployed in a Multi-AZ instance deployment to create an Amazon Aurora database. Direct the reporting functions to the reader instances.
- B. Use Amazon RDS deployed in a Multi-AZ cluster deployment to create an Oracle database Direct the reporting functions to use the reader instance in the cluster deployment
- C. Use AWS Database Migration Service (AWS DMS) to create an Amazon RDS DB instance in multiple AWS Regions Point the reporting functions toward a separate DB instance from the primary DB instance.
- D. Use Amazon RDS in a Single-AZ deployment to create an Oracle database Create a read replica in the same zone as the primary DB instance. Direct the reporting functions to the read replica.
Answer: A
Explanation:
B) Use Amazon RDS in a Single-AZ deployment to create an Oracle database Create a read replica in the same zone as the primary DB instance. Direct the reporting functions to the read replica. This solution will not meet the requirement of achieving higher availability, as a Single-AZ deployment does not provide failover protection in case of an Availability Zone outage. It also involves using Oracle as the database engine, which may not provide better performance than Aurora.
C) Use Amazon RDS deployed in a Multi-AZ cluster deployment to create an Oracle database Di-rect the reporting functions to use the reader instance in the cluster deployment. This solution will not meet the requirement of improving application performance, as Oracle may not provide better performance than Aurora. It also involves using a cluster deployment, which is only supported for Aurora, not for Oracle.
Reference URL: https://aws.amazon.com/rds/aurora/
Explanation:
Amazon Aurora is a fully managed relational database that is compatible with MySQL and PostgreSQL. It provides up to five times better performance than MySQL and up to three times better performance than PostgreSQL. It also provides high availability and durability by replicating data across multiple Availability Zones and continuously backing up data to Amazon S31. By using Amazon RDS deployed in a Multi-AZ instance deployment to create an Amazon Aurora database, the solution can achieve higher availability and improve application performance.
Amazon Aurora supports read replicas, which are separate instances that share the same underlying storage as the primary instance. Read replicas can be used to offload read-only queries from the primary instance and improve performance. Read replicas can also be used for reporting functions2. By directing the reporting functions to the reader instances, the solution can offload reporting from its primary database system.
A) Use AWS Database Migration Service (AWS DMS) to create an Amazon RDS DB instance in multiple AWS Regions Point the reporting functions toward a separate DB instance from the pri-mary DB instance. This solution will not meet the requirement of using an AWS database service, as AWS DMS is a service that helps users migrate databases to AWS, not a database service itself. It also involves creating multiple DB instances in different Regions, which may increase complexity and cost.
NEW QUESTION # 234
A company's reporting system delivers hundreds of .csv files to an Amazon S3 bucket each day. The company must convert these files to Apache Parquet format and must store the files in a transformed data bucket.
Which solution will meet these requirements with the LEAST development effort?
- A. Use AWS Batch to create a job definition with Bash syntax to transform the data and output the data to the transformed data bucket. Use the job definition to submit a job. Specify an array job as the job type.
- B. Create an AWS Glue crawler to discover the data. Create an AWS Glue extract, transform, and load (ETL) job to transform the data. Specify the transformed data bucket in the output step.
- C. Create an AWS Lambda function to transform the data and output the data to the transformed data bucket. Configure an event notification for the S3 bucket. Specify the Lambda function as the destination for the event notification.
- D. Create an Amazon EMR cluster with Apache Spark installed. Write a Spark application to transform the data. Use EMR File System (EMRFS) to write files to the transformed data bucket.
Answer: B
Explanation:
Explanation
https://docs.aws.amazon.com/prescriptive-guidance/latest/patterns/three-aws-glue-etl-job-types-for-converting-d
NEW QUESTION # 235
A research laboratory needs to process approximately 8 TB of data The laboratory requires sub-millisecond latencies and a minimum throughput of 6 GBps for the storage subsystem Hundreds of Amazon EC2 instances that run Amazon Linux will distribute and process the data Which solution will meet the performance requirements?
- A. Create an Amazon S3 bucket to stofe the raw data Create an Amazon FSx for Lustre file system that uses persistent SSD storage Select the option to import data from and export data to Amazon S3 Mount the file system on the EC2 instances
- B. Create an Amazon FSx for NetApp ONTAP file system Set each volume's tiering policy to ALL Import the raw data into the file system Mount the file system on the EC2 instances
- C. Create an Amazon S3 bucket to store the raw data Create an Amazon FSx for Lustre file system that uses persistent HDD storage Select the option to import data from and export data to Amazon S3 Mount the file system on the EC2 instances
- D. Create an Amazon FSx for NetApp ONTAP file system Set each volume's tienng policy to NONE.
Import the raw data into the file system Mount the file system on the EC2 instances
Answer: A
Explanation:
Explanation
Create an Amazon S3 bucket to store the raw data Create an Amazon FSx for Lustre file system that uses persistent SSD storage Select the option to import data from and export data to Amazon S3 Mount the file system on the EC2 instances. Amazon FSx for Lustre uses SSD storage for sub-millisecond latencies and up to
6 GBps throughput, and can import data from and export data to Amazon S3. Additionally, the option to select persistent SSD storage will ensure that the data is stored on the disk and not lost if the file system is stopped.
NEW QUESTION # 236
A company is designing a cloud communications platform that is driven by APIs. The application is hosted on Amazon EC2 instances behind a Network Load Balancer (NLB). The company uses Amazon API Gateway to provide external users with access to the application through APIs. The company wants to protect the platform against web exploits like SQL injection and also wants to detect and mitigate large, sophisticated DDoS attacks.
Which combination of solutions provides the MOST protection? (Select TWO.)
- A. Use Amazon GuardDuty with AWS Shield Standard.
- B. Use AWS Shield Advanced with the NLB.
- C. Use AWS WAF to protect Amazon API Gateway.
- D. Use AWS Shield Standard with Amazon API Gateway.
- E. Use AWS WAF to protect the NLB.
Answer: B,C
Explanation:
Explanation
AWS Shield Advanced provides expanded DDoS attack protection for your Amazon EC2 instances, Elastic Load Balancing load balancers, CloudFront distributions, Route 53 hosted zones, and AWS Global Accelerator standard accelerators.
AWS WAF is a web application firewall that lets you monitor the HTTP and HTTPS requests that are forwarded to your protected web application resources. You can protect the following resource types:
Amazon CloudFront distribution
Amazon API Gateway REST API
Application Load Balancer
AWS AppSync GraphQL API
Amazon Cognito user pool
https://docs.aws.amazon.com/waf/latest/developerguide/what-is-aws-waf.html
NEW QUESTION # 237
A solutions architect needs to design a system to store client case files. The files are core company assets and are important. The number of files will grow over time.
The files must be simultaneously accessible from multiple application servers that run on Amazon EC2 instances. The solution must have built-in redundancy.
Which solution meets these requirements?
- A. Amazon Elastic File System (Amazon EFS)
- B. Amazon Elastic Block Store (Amazon EBS)
- C. Amazon S3 Glacier Deep Archive
- D. AWS Backup
Answer: A
Explanation:
Explanation
Amazon EFS provides a simple, scalable, fully managed file system that can be simultaneously accessed from multiple EC2 instances and provides built-in redundancy. It is optimized for multiple EC2 instances to access the same files, and it is designed to be highly available, durable, and secure. It can scale up to petabytes of data and can handle thousands of concurrent connections, and is a cost-effective solution for storing and accessing large amounts of data.
NEW QUESTION # 238
A company s order system sends requests from clients to Amazon EC2 instances The EC2 instances process the orders and men store the orders in a database on Amazon RDS Users report that they must reprocess orders when the system fails. The company wants a resilient solution that can process orders automatically it a system outage occurs.
What should a solutions architect do to meet these requirements?
- A. Move the EC2 instances into an Auto Scaling group Configure the order system to send messages to an Amazon Simple Queue Service (Amazon SQS) queue Configure the EC2 instances to consume messages from the queue
- B. Move the EC2 instances into an Auto Scaling group behind an Application Load Balancer (ALB) Update the order system to send messages to the ALB endpoint.
- C. Create an Amazon Simple Notification Service (Amazon SNS) topic Create an AWS Lambda function, and subscribe the function to the SNS topic Configure the order system to send messages to the SNS topic Send a command to the EC2 instances to process the messages by using AWS Systems Manager Run Command
- D. Move (he EC2 Instances into an Auto Scaling group Create an Amazon EventBridge (Amazon CloudWatch Events) rule to target an Amazon Elastic Container Service (Amazon ECS) task
Answer: A
Explanation:
To meet the company's requirements of having a resilient solution that can process orders automatically in case of a system outage, the solutions architect needs to implement a fault-tolerant architecture. Based on the given scenario, a potential solution is to move the EC2 instances into an Auto Scaling group and configure the order system to send messages to an Amazon Simple Queue Service (Amazon SQS) queue. The EC2 instances can then consume messages from the queue.
NEW QUESTION # 239
A company stores its data on premises. The amount of data is growing beyond the company's available capacity.
The company wants to migrate its data from the on-premises location to an Amazon S3 bucket The company needs a solution that will automatically validate the integrity of the data after the transfer Which solution will meet these requirements?
- A. Order an AWS Snowball Edge device Configure the Snowball Edge device to perform the online data transfer to an S3 bucket.
- B. Create an Amazon S3 File Gateway on premises. Configure the S3 File Gateway to perform the online data transfer to an S3 bucket
- C. Configure an accelerator in Amazon S3 Transfer Acceleration on premises. Configure the accelerator to perform the online data transfer to an S3 bucket.
- D. Deploy an AWS DataSync agent on premises. Configure the DataSync agent to perform the online data transfer to an S3 bucket.
Answer: D
Explanation:
it allows the company to migrate its data from the on-premises location to an Amazon S3 bucket and automatically validate the integrity of the data after the transfer. By deploying an AWS DataSync agent on premises, the company can use a fully managed data transfer service that makes it easy to move large amounts of data to and from AWS. By configuring the DataSync agent to perform the online data transfer to an S3 bucket, the company can take advantage of DataSync's features, such as encryption, compression, bandwidth throttling, and data validation. DataSync automatically verifies data integrity at both source and destination after each transfer task. Reference:
AWS DataSync
Deploying an Agent for AWS DataSync
How AWS DataSync Works
NEW QUESTION # 240
A company has two VPCs named Management and Production. The Management VPC uses VPNs through a customer gateway to connect to a single device in the data center. The Production VPC uses a virtual private gateway AWS Direct Connect connections. The Management and Production VPCs both use a single VPC peering connection to allow communication between the What should a solutions architect do to mitigate any single point of failure in this architecture?
- A. Add a second set of VPNs to the Management VPC from a second customer gateway device.
- B. Add a set of VPNs between the Management and Production VPCs.
- C. Add a second virtual private gateway and attach it to the Management VPC.
- D. Add a second VPC peering connection between the Management VPC and the Production VPC.
Answer: A
Explanation:
This answer is correct because it provides redundancy for the VPN connection between the Management VPC and the data center. If one customer gateway device or one VPN tunnel becomes unavailable, the traffic can still flow over the second customer gateway device and the second VPN tunnel. This way, the single point of failure in the VPN connection is mitigated.
Reference:
https://docs.aws.amazon.com/vpn/latest/s2svpn/vpn-redundant-connection.html
https://www.trendmicro.com/cloudoneconformity/knowledge-base/aws/VPC/vpn-tunnel-redundancy.html
NEW QUESTION # 241
A company runs a containerized application on a Kubernetes cluster in an on-premises data center. The company is using a MongoDB database for data storage.
The company wants to migrate some of these environments to AWS, but no code changes or deployment method changes are possible at this time. The company needs a solution that minimizes operational overhead.
Which solution meets these requirements?
- A. Use Amazon Elastic Container Service (Amazon ECS) with AWS Fargate for compute and Amazon DynamoDB for data storage.
- B. Use Amazon Elastic Kubernetes Service (Amazon EKS) with Amazon EC2 worker nodes for compute and Amazon DynamoDB for data storage.
- C. Use Amazon Elastic Kubernetes Service (Amazon EKS) with AWS Fargate for compute and Amazon DocumentDB (with MongoDB compatibility) for data storage.
- D. Use Amazon Elastic Container Service (Amazon ECS) with Amazon EC2 worker nodes for compute and MongoDB on EC2 for data storage.
Answer: C
Explanation:
Explanation
Amazon DocumentDB (with MongoDB compatibility) is a fast, reliable, and fully managed database service.
Amazon DocumentDB makes it easy to set up, operate, and scale MongoDB-compatible databases in the cloud. With Amazon DocumentDB, you can run the same application code and use the same drivers and tools that you use with MongoDB.
https://docs.aws.amazon.com/documentdb/latest/developerguide/what-is.html
NEW QUESTION # 242
An ecommerce company has an order-processing application that uses Amazon API Gateway and an AWS Lambda function. The application stores data in an Amazon Aurora PostgreSQL database. During a recent sales event, a sudden surge in customer orders occurred. Some customers experienced timeouts and the application did not process the orders of those customers A solutions architect determined that the CPU utilization and memory utilization were high on the database because of a large number of open connections The solutions architect needs to prevent the timeout errors while making the least possible changes to the application.
Which solution will meet these requirements?
- A. Configure provisioned concurrency for the Lambda function Modify the database to be a global database in multiple AWS Regions
- B. Create a read replica for the database in a different AWS Region Use query string parameters in API Gateway to route traffic to the read replica
- C. Use Amazon RDS Proxy to create a proxy for the database Modify the Lambda function to use the RDS Proxy endpoint instead of the database endpoint
- D. Migrate the data from Aurora PostgreSQL to Amazon DynamoDB by using AWS Database Migration Service (AWS DMS| Modify the Lambda function to use the OynamoDB table
Answer: D
NEW QUESTION # 243
A company is preparing to deploy a new serverless workload. A solutions architect must use the principle of least privilege to configure permissions that will be used to run an AWS Lambda function. An Amazon EventBridge (Amazon CloudWatch Events) rule will invoke the function.
Which solution meets these requirements?
- A. Add a resource-based policy to the function with lambda:InvokeFunction as the action and Service:events.amazonaws.com as the principal.
- B. Add an execution role to the function with lambda:InvokeFunction as the action and * as the principal.
- C. Add a resource-based policy to the function with lambda:'* as the action and Service:events.amazonaws.com as the principal.
- D. Add an execution role to the function with lambda:InvokeFunction as the action and Service:amazonaws.com as the principal.
Answer: A
Explanation:
Explanation
https://docs.aws.amazon.com/eventbridge/latest/userguide/resource-based-policies-eventbridge.html#lambda-per
NEW QUESTION # 244
A solutions architect is designing a two-tier web application The application consists of a public-facing web tier hosted on Amazon EC2 in public subnets The database tier consists of Microsoft SQL Server running on Amazon EC2 in a private subnet Security is a high priority for the company How should security groups be configured in this situation? (Select TWO )
- A. Configure the security group for the database tier to allow inbound traffic on ports 443 and 1433 from the security group for the web tier.
- B. Configure the security group for the web tier to allow inbound traffic on port 443 from 0.0.0.0/0.
- C. Configure the security group for the database tier to allow inbound traffic on port 1433 from the security group for the web tier.
- D. Configure the security group for the database tier to allow outbound traffic on ports 443 and 1433 to the security group for the web tier.
- E. Configure the security group for the web tier to allow outbound traffic on port 443 from 0.0.0.0/0.
Answer: B,C
Explanation:
"Security groups create an outbound rule for every inbound rule." Not completely right. Statefull does NOT mean that if you create an inbound (or outbound) rule, it will create an outbound (or inbound) rule. What it does mean is: suppose you create an inbound rule on port 443 for the X ip. When a request enters on port 443 from X ip, it will allow traffic out for that request in the port 443. However, if you look at the outbound rules, there will not be any outbound rule on port 443 unless explicitly create it. In ACLs, which are stateless, you would have to create an inbound rule to allow incoming requests and an outbound rule to allow your application responds to those incoming requests.
https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html#SecurityGroupRules
NEW QUESTION # 245
A manufacturing company launched a new type of IoT sensor. The sensor will be used to collect large streams of data records. You need to create a solution that can ingest and analyze the data in real- time with millisecond response times.
Which of the following is the best option that you should implement in this scenario?
- A. Ingest the data using Amazon Kinesis Data Streams and create an AWS Lambda function to store the data in Amazon DynamoDB.
- B. Ingest the data using Amazon Simple Queue Service and create an AWS Lambda function to store the data in Amazon Redshift.
- C. Ingest the data using Amazon Kinesis Data Firehose and create an AWS Lambda function to store the data in Amazon DynamoDB.
- D. Ingest the data using Amazon Kinesis Data Streams and create an AWS Lambda function to store the data in Amazon Redshift.
Answer: A
Explanation:
Amazon Kinesis Data Streams enables you to build custom applications that process or analyze streaming data for specialized needs. You can continuously add various types of data such as clickstreams, application logs, and social media to an Amazon Kinesis data stream from hundreds of thousands of sources. Within seconds, the data will be available for your Amazon Kinesis Applications to read and process from the stream.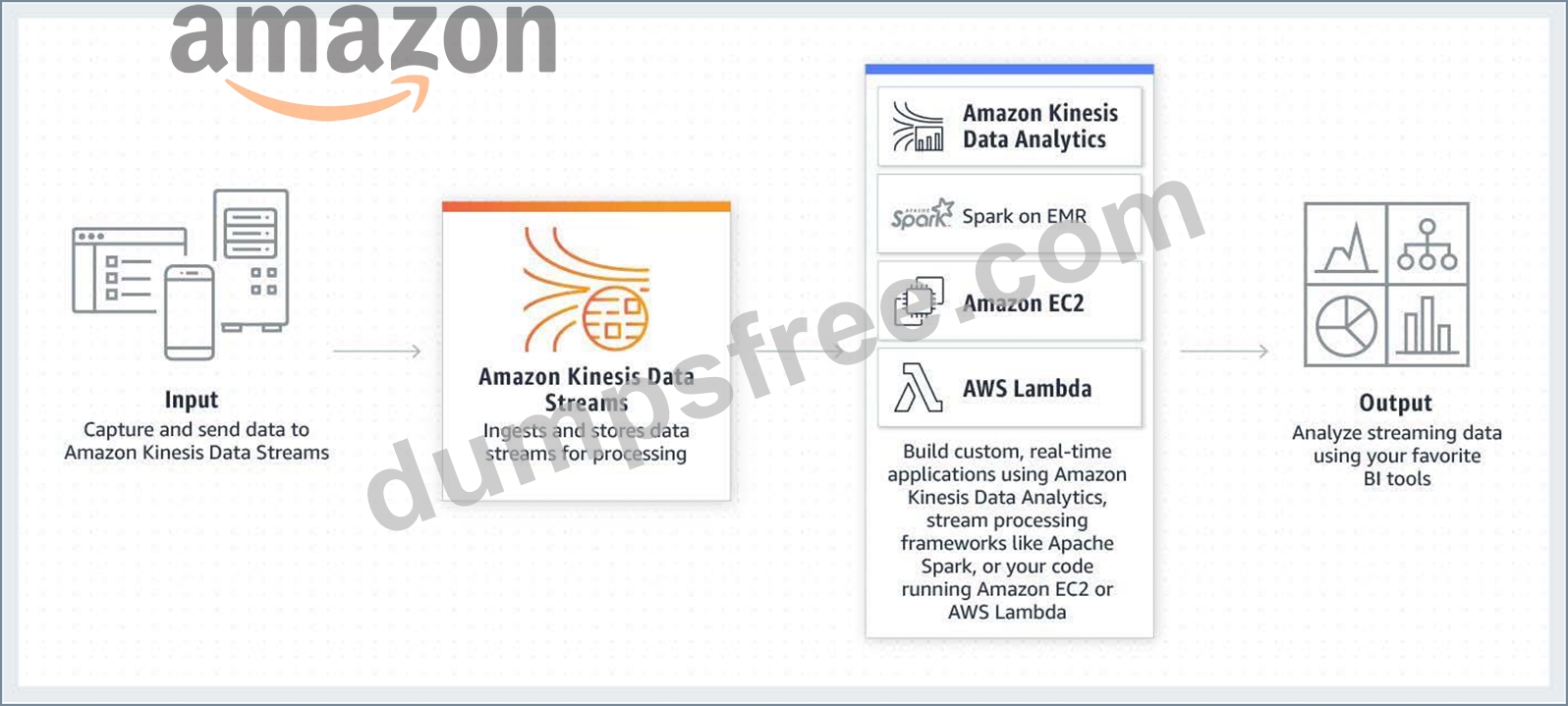
Based on the given scenario, the key points are "ingest and analyze the data in real-time" and
"millisecond response times". For the first key point and based on the given options, you can use Amazon Kinesis Data Streams because it can collect and process large streams of data records in real- time. For the second key point, you should use Amazon DynamoDB since it supports single-digit millisecond response times at any scale.
Hence, the correct answer is: Ingest the data using Amazon Kinesis Data Streams and create an AWS Lambda function to store the data in Amazon DynamoDB.
The option that says: Ingest the data using Amazon Kinesis Data Streams and create an AWS Lambda function to store the data in Amazon Redshift is incorrect because Amazon Redshift only delivers sub- second response times. Take note that as per the scenario, the solution must have millisecond response times to meet the requirements. Amazon DynamoDB Accelerator (DAX), which is a fully managed, highly available, in-memory cache for Amazon DynamoDB, can deliver microsecond response times.
The option that says: Ingest the data using Amazon Kinesis Data Firehose and create an AWS Lambda function to store the data in Amazon DynamoDB is incorrect. Amazon Kinesis Data Firehose only supports Amazon S3, Amazon Redshift, Amazon Elasticsearch, and an HTTP endpoint as the destination.
The option that says: Ingest the data using Amazon Simple Queue Service and create an AWS Lambda function to store the data in Amazon Redshift is incorrect because Amazon SQS can't analyze data in real-time. You have to use an Amazon Kinesis Data Stream to process the data in near-real-time.
References:
https://aws.amazon.com/kinesis/data-streams/faqs/
https://aws.amazon.com/dynamodb/
Check out this Amazon Kinesis Cheat Sheet:
https://tutorialsdojo.com/amazon-kinesis/
NEW QUESTION # 246
A company is implementing a shared storage solution for a media application that is hosted m the AWS Cloud The company needs the ability to use SMB clients to access data The solution must he fully managed.
Which AWS solution meets these requirements?
- A. Create an Amazon EC2 Windows instance Install and configure a Windows file share role on the instance. Connect the application server to the file share.
- B. Create an AWS Storage Gateway tape gateway Configure (apes to use Amazon S3 Connect the application server lo the tape gateway
- C. Create an AWS Storage Gateway volume gateway. Create a file share that uses the required client protocol Connect the application server to the file share.
- D. Create an Amazon FSx for Windows File Server tile system Attach the fie system to the origin server. Connect the application server to the file system
Answer: D
Explanation:
https://aws.amazon.com/fsx/lustre/
Amazon FSx has native support for Windows file system features and for the industry-standard Server Message Block (SMB) protocol to access file storage over a network. https://docs.aws.amazon.com/fsx/latest/WindowsGuide/what-is.html
NEW QUESTION # 247
......
Fully Updated Dumps PDF - Latest SAA-C03 Exam Questions and Answers: https://www.dumpsfree.com/SAA-C03-valid-exam.html
100% Free SAA-C03 Exam Dumps to Pass Exam Easily: https://drive.google.com/open?id=1S2_kvxeYs-UT-lfSsc6230Is8xn04y5y